Drupal CI/CD Workflow Setup with Visual Regression Testing
Image

Setting up a reliable Drupal continuous integration and continuous deployment (CI/CD) pipeline is harder than it looks. A build that passes every local test can still fail once it reaches a real hosting environment.
But don’t worry – in this guide, we’ll explain why that happens and how to design a pipeline that works with those constraints. You’ll learn how to plan environments first, create immutable build artifacts, run automated and visual regression tests on temporary previews and deploy using the platform’s own tools.
By the end, you should end up with a process you can trust across providers, without surprises or endless debugging sessions.
Why your pipeline works locally but fails in production
A Drupal CI/CD pipeline can succeed in every local test and still fail when deployed because production hosting environments operate under conditions that local machines rarely replicate, such as:
- Read-only docroot: Most managed Drupal hosts mount the web root as read-only during runtime. Any build process that writes files – generating CSS, creating symlinks or altering settings.php – will fail. All asset compilation and configuration changes must occur before deployment, producing an immutable build artifact.
- Fixed resource limits: Production containers often enforce strict memory, CPU and process caps. PHP settings such as max_execution_time or memory_limit may be lower than on a developer’s workstation. Queries or asset builds that pass locally can exceed these limits and terminate unexpectedly.
- Managed services and routing layers: Database clusters, object caches and edge routing introduce latency and connection constraints. Operations like configuration imports or large schema updates can require ordered execution and retry logic to avoid timeouts.
- Immutable infrastructure: Environments are rebuilt from version control. Any manual patch – editing files over SSH, hot-fixing configuration – vanishes on the next deploy and pipelines that assume persistent state will break.
To build dependable deployments, the CI system must orchestrate with these platform constraints. That means preparing artifacts in CI, promoting them through controlled environments and using platform-provided CLI (like Pantheon’s Terminus) or APIs for tasks such as database updates and cache clears.
Shifting from “CI controls everything” to “CI orchestrates the platform”
Continuous integration is often treated as the single authority: build the code, copy it to a server, run some commands and call it done. That model collapses when the hosting platform has its own infrastructure rules.
A more durable approach treats CI as a coordinator and the platform as the executor. The CI runner assembles an immutable build artifact, verifies it through automated tests and then instructs the platform – via its API or CLI – to deploy the artifact, run database updates, clear caches and manage environment lifecycles. The platform handles the scaling, routing and persistent storage because that is what it’s built to do.
Before adopting this model, confirm you can:
- Run Composer to install dependencies and create build artifacts.
- Run Drush for database updates, cache clears and configuration imports.
- Use your host’s CLI (for example, Pantheon’s Terminus) for environment creation, deployment and cleanup.
- Store API tokens or SSH keys as encrypted CI secrets so the pipeline can authenticate without exposing credentials.
Here are some anti-patterns to avoid:
- Writing to the docroot during deployment: Managed hosts keep the web root read-only at runtime. Generating CSS, moving files or editing settings here will fail or be overwritten.
- Long-lived “snowflake” servers: Manual tweaks outside version control disappear when environments are rebuilt.
- Direct SSH changes in production: Editing code or configuration live bypasses the platform’s deployment workflow and breaks reproducibility.
By reframing CI as an orchestrator and respecting the platform’s contract, deployments become predictable and repeatable.
Architecting environments before pipelines
The structure of your hosting environments determines how every CI/CD job is defined and how much the pipeline will cost to operate. Plan the environments first – the pipeline should fit around them, not the other way around.
A typical production-ready path is dev → test/stage → prod, with short-lived preview environments for each feature branch or merge request:
- Development (dev): Where active coding and integration happen.
- Test/Stage: A stable space for QA, client demos and pre-release validation.
- Production: The live site, protected with strict permissions.
- Preview/ephemeral: On-demand copies of the site are created automatically for each branch so reviewers can test real code before it merges.
This arrangement supports early testing, controlled promotions and clear approval gates while avoiding uncontrolled sprawl.
For example, on Pantheon, you can use Multidev to create ephemeral preview environments. The webroot is read-only at runtime and databases/files are provided as managed services, so every preview is consistent with production.
Image
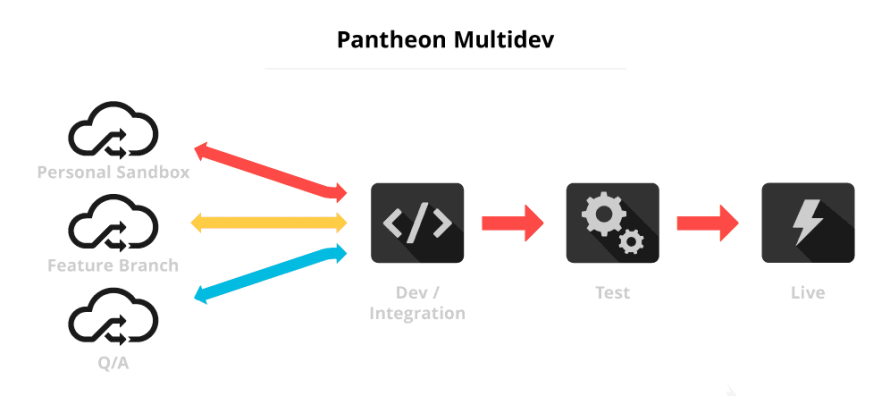
Bear in mind, Ephemeral environments are powerful but can quickly exhaust quotas or budgets if left running. Helpful patterns include:
- Time-to-live (TTL) cleanup: Automatically delete environments after a fixed duration – 24 or 48 hours is common.
- Merge-request close hooks: Destroy the preview environment as soon as the branch merges or closes.
- Nightly sweep job: A scheduled CI task that removes inactive or abandoned environments.
These safeguards keep resource usage predictable while preserving the flexibility of on-demand testing.
The four stages of Drupal CI/CD
A solid Drupal CI/CD workflow follows four repeatable stages. Each stage has a clear purpose and outputs that feed the next, giving you predictable, traceable deployments.
Build
The build phase compiles everything your site needs into a single, immutable artifact before we even think about running or testing the website. That includes the core Drupal system, any extra modules you’ve installed (both from the community and ones you've written yourself) and libraries those modules depend on.
Drupal sites usually manage these dependencies using Composer. Use ‘composer install’ with the composer.lock file to make sure everyone – and every environment – is using exactly the same versions of everything.
Additionally, this stage handles tasks like compiling your CSS and JavaScript if you're using tools like Sass or Webpack.
Don’t include files that are only useful during development when building the artifact (the packaged version of your site). You want a clean, lean version of the site that can be deployed as-is, without needing to clean anything up afterward.
Test
The test stage is where you verify automatically that the artifact behaves correctly before it reaches a live environment.
There are several types of tests in a modern Drupal project, each looking at the site from a different angle:
- Unit and kernel tests with PHPUnit (back-end logic): Unit tests are the most focused type of test, focusing on small pieces of your code (like a single function or class) and checking that they behave correctly under different conditions. For example, if you wrote a function that calculates tax or filters content, a unit test will run that function with different inputs and make sure the results are what you expect.
- Behavior tests with Behat (simulating real user flows): Behat tests focus on the user experience, simulating how a real user would interact with your website.
- Static analysis with PHPStan and PHP_CodeSniffer (code cleanliness): PHPStan looks for bugs and logic issues just by reading the code before it's executed. It can catch things like calling a method on a null object or using the wrong data type – issues that might not cause immediate errors but could lead to broken behavior down the road. PHP_CodeSniffer checks your code against coding standards – in this case, Drupal’s own style guidelines. It ensures that your code is not just functional, but also clean, consistent and easy for other developers to understand.
- Visual regression testing (catching front-end surprises): Visual regression testing (VRT) works by taking screenshots of your site before and after a change, then comparing them pixel by pixel. If something suddenly shifts – like a button disappears or the layout breaks – the test flags it. This is especially useful when working with themes, front-end components or responsive layouts. We’ll cover this in more detail later in the article.
Release
The release stage is where the tested artifact is packaged up in a way that can be easily deployed, tracked and (if needed) rolled back.
The process typically begins by tagging the specific commit or build artifact with a version number (e.g., v1.2.0). This tag acts as a reference point in version control, allowing teams to identify exactly which version of the code was used to generate the build artifact. Version tags support better coordination between developers, QA and operations teams and serve as historical markers in the release lifecycle.
Next, metadata is attached to the release artifact. This may include the Git SHA – a unique identifier for the commit – along with a software bill of materials (SBOM). The SBOM provides a comprehensive list of all dependencies, modules and packages used in the build. This improves transparency, helps with security vulnerability tracking and supports regulatory compliance by showing exactly what components are in use.
To protect the integrity of the artifact, it is often digitally signed or paired with a checksum (such as SHA-256). These mechanisms confirm that the artifact has not been altered since it was created. Any change, even accidental, would result in a mismatch and alert the team to possible tampering or corruption. Integrity checks also facilitate quick identification and comparison of releases.
Deploy
The deploy stage is the final and most critical part of the CI/CD pipeline, where all the validated and tested changes are released into a target environment – such as staging or production. At this point, the application is assumed to be stable and the goal is to transfer it safely and efficiently into the live environment without introducing downtime or errors.
Deployment begins by promoting the prepared build (also called the artifact) into the desired environment. This artifact includes the full Drupal codebase along with its dependencies and compiled assets. Deployment tools – provided by Pantheon, for instance – are used to move the artifact. These tools may come in the form of a CLI or API, allowing for automated and consistent releases across environments.
Once the artifact has been deployed, several important Drupal-specific maintenance operations must be performed to ensure the system functions correctly with the new code and configuration:
- drush updb – applies any pending database schema updates defined in the code (via hook_update_N() functions). These updates might include adding new database tables, modifying existing ones or altering data structures to match the new application logic.
- drush cim – stands for Configuration Import. It synchronizes configuration changes (like new content types, updated permissions or altered views) from the exported files into the database. This ensures that the live site reflects the intended structure and behavior defined during development.
- drush cr – clears and rebuilds Drupal’s caches. Since Drupal relies heavily on caching for performance, it's essential to flush outdated data from the system so new changes are recognized immediately. This includes theme changes, configuration updates and routing definitions.
After the deployment and Drupal maintenance tasks are complete, post-deploy checks are performed to verify that the site is functioning as expected. These checks can include:
- Verifying that all critical services (database, search, caching layers) are running.
- Confirming that the configuration was successfully imported and that no errors occurred during updates.
- Running smoke tests or pinging key routes to ensure the site responds correctly.
To enhance performance, cache warming is often conducted at this stage. Cache warming means programmatically visiting important pages or routes on the site to preload them into the cache, ensuring that the first real users don’t experience delays caused by an empty cache.
Skipping or reordering these stages creates hidden inconsistencies. Testing code before the final build can miss dependency or asset issues. Releasing without tests removes the guarantee that a tagged version actually works. Deploying before a formal release makes rollback impossible.
Drupal also adds extra sensitivity:
- Configuration sync timing – decide whether to run database updates before or after configuration imports, depending on schema changes.
- Entity updates – some module updates require specific ordering or manual intervention.
- Read-only filesystem – all build steps must occur before deployment; never write to the docroot at runtime.
- Binary files in config – handle image styles or file-based configuration carefully to avoid mismatches.
- Large asset builds – cache Composer and front-end dependencies to keep build times manageable.
Choosing a CI service that fits your hosting platform
A Drupal pipeline doesn’t depend on one specific CI tool. A lot of tools can build, test and deploy Drupal sites. For example:
- GitLab CI – integrated with GitLab’s repository management. Powerful YAML-based pipelines, built-in caching, parallel test jobs and free shared runners.
- GitHub Actions – tight coupling with GitHub repos, marketplace of reusable actions, generous free minutes for open source.
- CircleCI – strong caching features and fast containerized runners; good for teams that want a managed service but need advanced configuration.
- Jenkins – fully self-hosted and highly extensible with plugins. Ideal when regulatory or security policies require everything on-premises.
The real question is how easily each service integrates with your hosting platform’s APIs, authentication and resource limits.
Choose a hosting model
First, decide where the runners will live. Managed (SaaS) services such as GitHub Actions (on Pantheon, for example), GitLab or CircleCI give you ready-to-use runners and automatic scaling. They reduce maintenance and are ideal when you just need reliable builds.
On the other hand, self-hosted tools such as Jenkins or GitLab Runner give full control over hardware and network access, which some organizations need for compliance or custom integrations.
This choice shapes everything else – how you secure secrets, how caching works and how you connect to your hosting provider.
Pantheon’s documented CI/CD guides and maintained GitHub Action make this integration straightforward, no matter which runner you prefer.
Plan for secrets and integration
Every Drupal pipeline must authenticate to the hosting platform to create environments and run deployment commands. Whichever CI service you select, confirm it supports:
- Encrypted environment variables or a secure vault for API tokens and SSH keys.
- Role-based access so only the pipeline – not individual developers – uses production credentials.
- Strong secret management is the bridge between your CI system and the platform.
Handle speed and scale
Next, look at how the service moves data and runs jobs:
- Caching: Composer and Node dependencies are large; built-in caching saves time and bandwidth.
- Artifacts: Your build will produce a sizeable tarball or container; ensure the service stores and passes it to later jobs.
- Parallelization: Unit tests, Behat scenarios and visual regression checks can run in parallel to shorten total build time.
These capabilities let the pipeline keep up as your project grows.
The key takeaway here is that, because the platform performs the deployment, your main requirement for the CI service is reliable integration with the platform’s CLI or API. Feature lists matter less than that single capability.
Visual regression testing (VRT) against real environment URLs
Up to this point, we’ve built and tested an immutable artifact, selected a CI service that talks to our host and defined a pipeline that promotes code through carefully planned environments.
Visual regression testing is the natural next layer – it proves that what users see in those environments matches expectations, not just that the code compiles or the database schema updates.
Running VRT on a developer laptop or a generic staging site only verifies a fraction of the real experience. Fonts, CDN headers, caching layers and image-style generation can all behave differently once the site sits behind a production-grade platform.
Because we already create ephemeral environments for each branch – with Pantheon’s Multidev, for instance – we can target those actual URLs. This connects directly to the environment strategy described earlier: every branch has a self-contained copy of code, database and files, making it the perfect place to capture screenshots and detect unintended changes.
Visual checks belong in the test stage, right after functional tests. The artifact you built is already frozen, so any change in appearance points to a real difference in the deployable package, not a quirk of the local build. Running against the preview environment also exercises the platform’s caching and routing layers, uncovering layout shifts or asset-loading problems that would never appear in a purely local container.
Key considerations here:
- Environment readiness – VRT should run only after the preview environment is fully deployed and caches are warm, otherwise, you compare half-rendered pages.
- Stable baselines – store reference images per branch or per mainline to avoid cross-branch noise.
- Deterministic output – lock fonts, locales and viewport sizes so screenshots are consistent across CI runners and hosting providers.
- Approval workflow – integrate with your merge or pull-request process so a human can approve visual changes before deployment.
Rollback patterns that save your reputation
Earlier, we emphasized immutable builds, environment parity and thorough testing – including visual regression tests against real preview URLs. Those steps dramatically reduce risk, but they can’t eliminate it. Production traffic, live data volumes and sudden platform issues may expose problems that never appeared in test or stage environments. Without a clear rollback path, every incident turns into an emergency.
Here are the core principles of a reliable rollback:
- Versioned releases: Because each deployment promotes an immutable artifact built from a tagged commit, you always know exactly which build is running and can redeploy a previous version without rebuilding it.
- Data-aware strategy: Separate code from content. Code rollbacks are straightforward, but database schema changes or configuration imports may require compensating scripts or a targeted “down migration.”
- Automated hooks with manual controls: Automation handles the common case – reverting to the last known good release – while human approval gates protect against making a bad situation worse.
These principles build directly on earlier sections: the build and release stages create the artifacts you can redeploy and the environment planning ensures you have a stable test/stage path to validate a rollback before touching production.
Recommended patterns include:
- One-command redeploy: Store at least the last few tagged artifacts and provide a CI job or platform CLI script that can instantly trigger a deployment using a specific tag.
- Database and file backups: Schedule automatic backups before each deploy. Pairing a code rollback with a corresponding database snapshot prevents schema mismatches.
- Automated triggers: Optional health checks or monitoring tools can invoke a rollback pipeline if they detect critical errors or sustained downtime.
- Manual intervention points: Always allow a team member to pause automation, review logs and decide whether a partial fix or full rollback is appropriate.
Your first successful deployment starts now
Modern Drupal teams need more than a build server – they need a platform built for continuous delivery.
Pantheon provides that foundation: immutable, read-only environments for predictable releases, Multidev for on-demand previews, managed databases and Redis for performance and the Terminus CLI for fully automated deployments and rollbacks.
By treating CI as the orchestrator and Pantheon as the executor, you eliminate the “works locally but fails in production” trap and gain a repeatable, testable release workflow from dev to live.
Start building a CI/CD pipeline that never surprises you with Pantheon today!