The Pantheon Blog
Brandfolder Image

Latest insights

Navigating the Noise: A Look at Bot Traffic on Pantheon
Read More
All's FAIR: Why WordPress needs decentralization
Read More
Pantheon protects you from the latest WordPress security exploits
Read More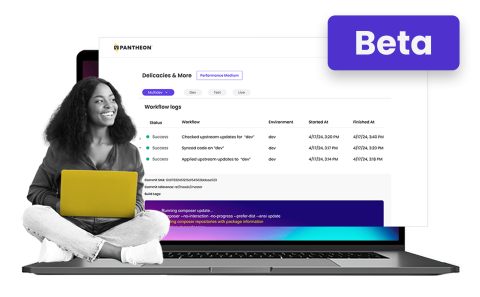
Modernizing Pantheon's Site Dashboard
Read More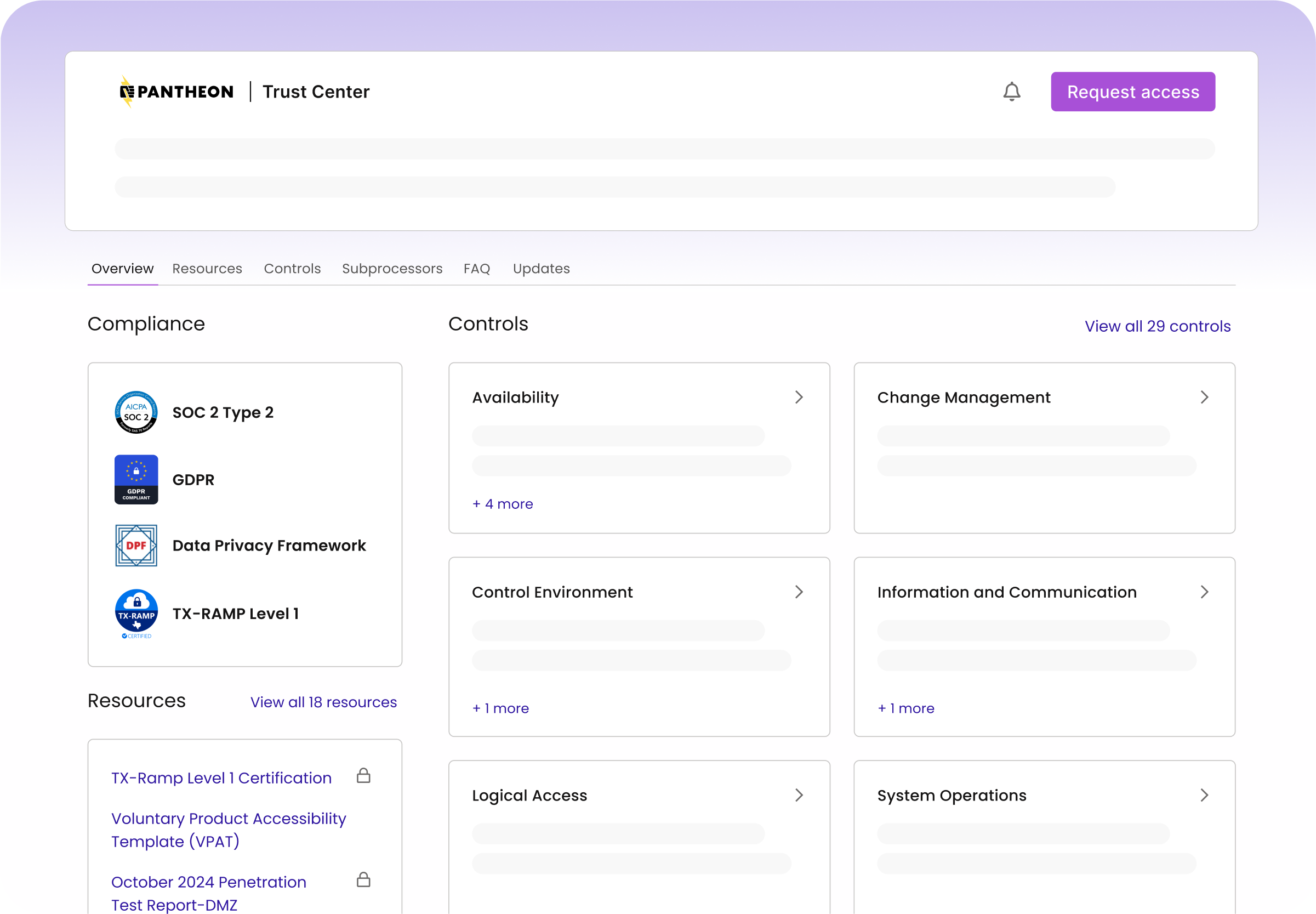
Introducing Pantheon’s Trust Center: Transparency Meets Performance
Read MoreWhy We Created a "Push to Pantheon" GitHub Action
Read More
Enhanced Drupal Integration for Content Publisher
Read More
A WordPresser goes to DrupalCon Atlanta 2025
Read More
Announcing 2025 Pantheon Partner Summit Award Winners
Read More
A New Era for Customer Experience: Introducing Pantheon’s CCO
Read More
Connecting Enrollment and Web Teams for Student Success
Read More
What's Cooking at Pantheon's DrupalCon Booth 2025
Read More